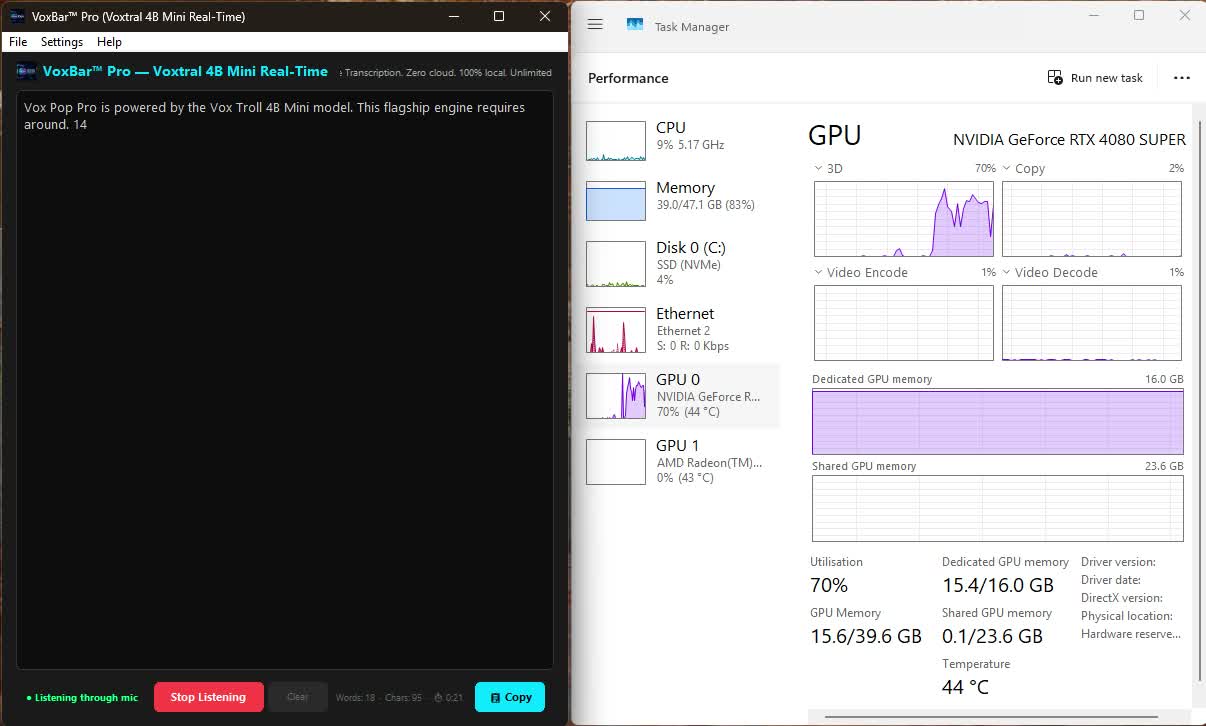
Flagship Engine
VoxBar Pro Docker (Voxtral 4B Real-Time Mini)
The sheer level of optimization achievable today is apparent. VoxBar Pro uses
around 14GB of Dedicated VRAM to comfortably run the Voxtral 4B
Min model.
As I speak these words, the model is processing my voice entirely locally, without
any internet connection. The Task Manager alongside demonstrates the live GPU utilization,
which barely exceeds 1% usage for instant sub-200 millisecond
transcription.
Native Engine — No Docker
VoxBar Pro Native (Voxtral F16 4B)
The same S-tier Voxtral 4B model as Pro Docker, but running natively on Windows
without Docker. This setup uses approximately
8.5GB of Dedicated
VRAM — a 40% reduction compared to the Docker variant.
Without Docker Desktop overhead, there is no WSL2 memory reservation, no container
daemon, and no WebSocket layer. The model loads directly onto the GPU via CUDA,
delivering identical transcription quality with significantly lower resource requirements.
Ideal for systems with 10–12GB VRAM GPUs.
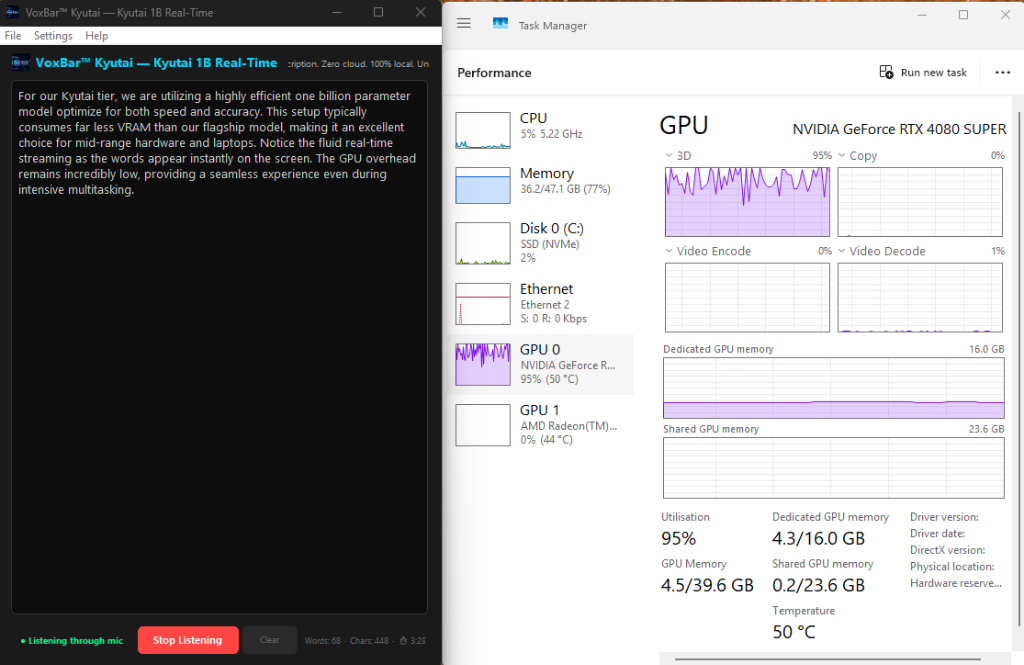
Real-Time Engine
VoxBar Kyutai (1B)
For our Kyutai tier, we are utilizing an efficiently packed 1 billion parameter model
optimized
for instant responsiveness. This setup requires around 2.7GB
of Dedicated
VRAM beyond your system’s idle baseline.
Making it an excellent choice for mid-range hardware and laptops, you will notice
fluid
streaming as the words appear rapidly on the screen. Because the model forces real-time
processing through a smaller pipe, it leverages around 95% GPU overhead
during
active speech bursts, while keeping the overall VRAM footprint incredibly low.
Advanced Real-Time Engine
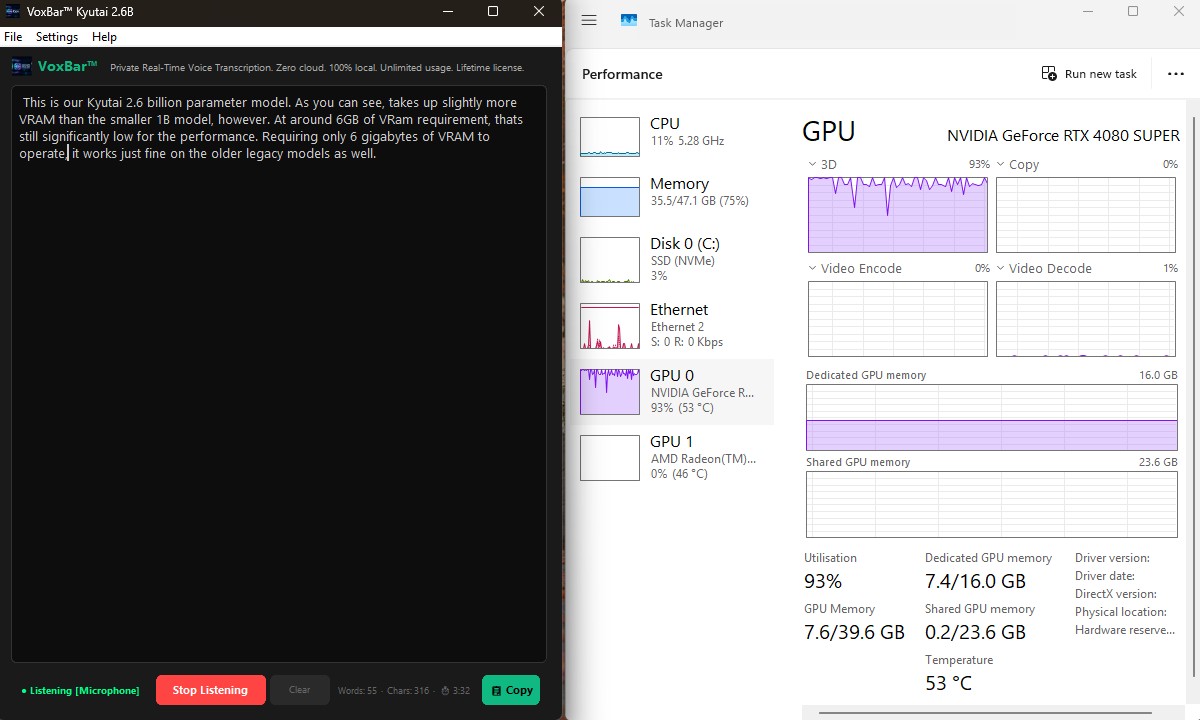
VoxBar Pro Kyutai (2.6B)
This is our Kyutai 2.6 billion parameter model. As you can see, it requires slightly more
VRAM
than our smaller 1B model, standing at around 5.8GB of
Dedicated
VRAM beyond the idle desktop baseline.
Requiring substantially more compute than the 1B variant, it pushes the GPU
overhead up
to 93% utilization while active. Still, staying comfortably around 6 GB of
VRAM
requirement means it works wonderfully on older legacy graphics cards as well, all while
offering higher reasoning and accuracy.
Ultra Fast Engine
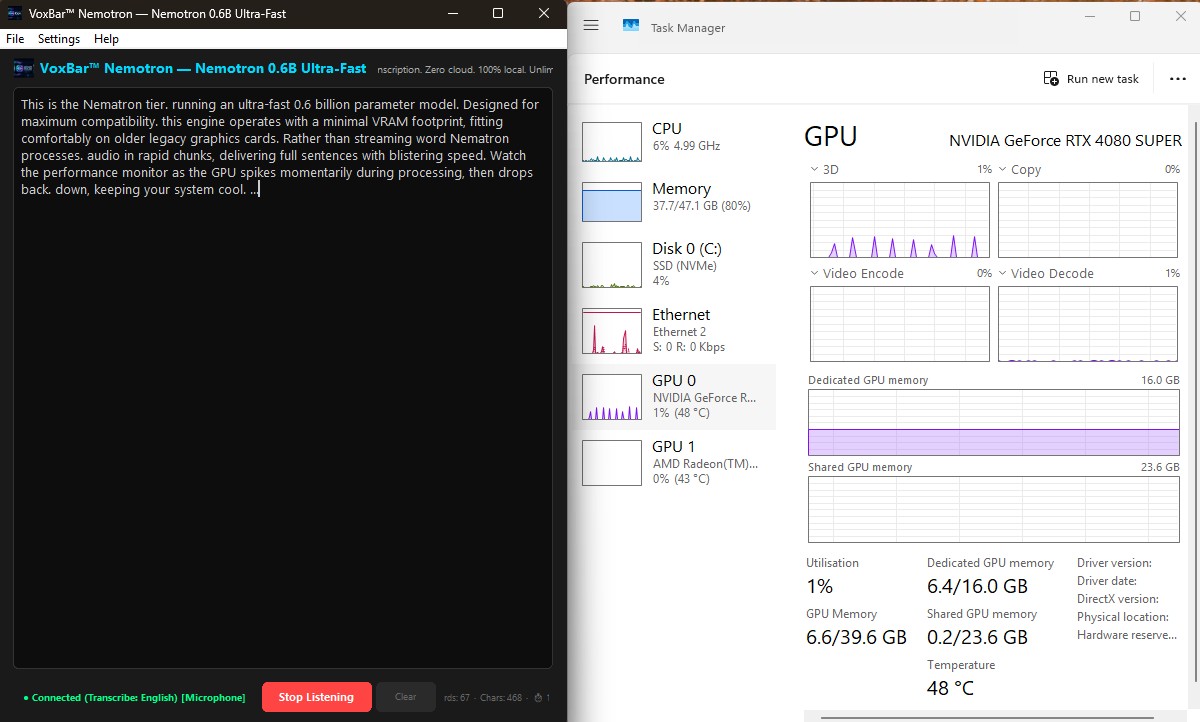
VoxBar Nemotron (0.6B)
This is the Nemotron tier, running an ultra-fast 0.6 billion parameter model. Designed for
maximum compatibility, this engine operates with a targeted VRAM footprint, utilizing about
4.8GB of Dedicated VRAM over the system’s baseline.
Rather than streaming word-by-word continuously, Nemotron processes audio in rapid
discrete chunks, delivering full sentences with blistering speed. Watch the performance
monitor
as the GPU spikes momentarily during processing (visible on the 3D graph), then drops
completely
back down to 1% utilization, keeping your system cool for background tasks.
High Accuracy Engine
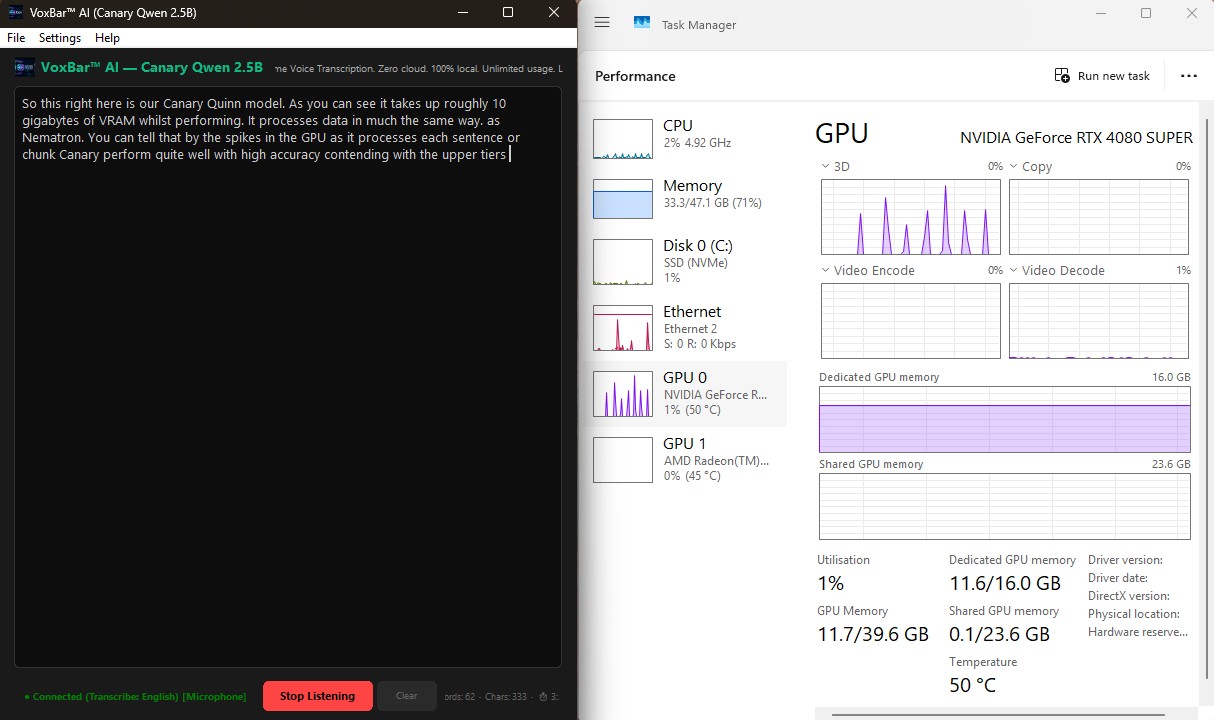
VoxBar AI (Canary Qwen 2.5B)
This right here is our Canary Qwen model. As you can see, it requires roughly 10GB
of Dedicated VRAM (beyond the desktop idle state) while
performing.
It processes data incrementally in chunks much like Nemotron, which you can tell by
the
momentary spikes in the GPU 3D utilization graph as it rapidly computes each sentence. Even
with
its larger memory footprint and higher complexity, it manages to drop back to 1%
utilization between bursts, offering unmatched accuracy capable of contending
with
the upper tiers without bottlenecking your system.
Fast High Accuracy Engine
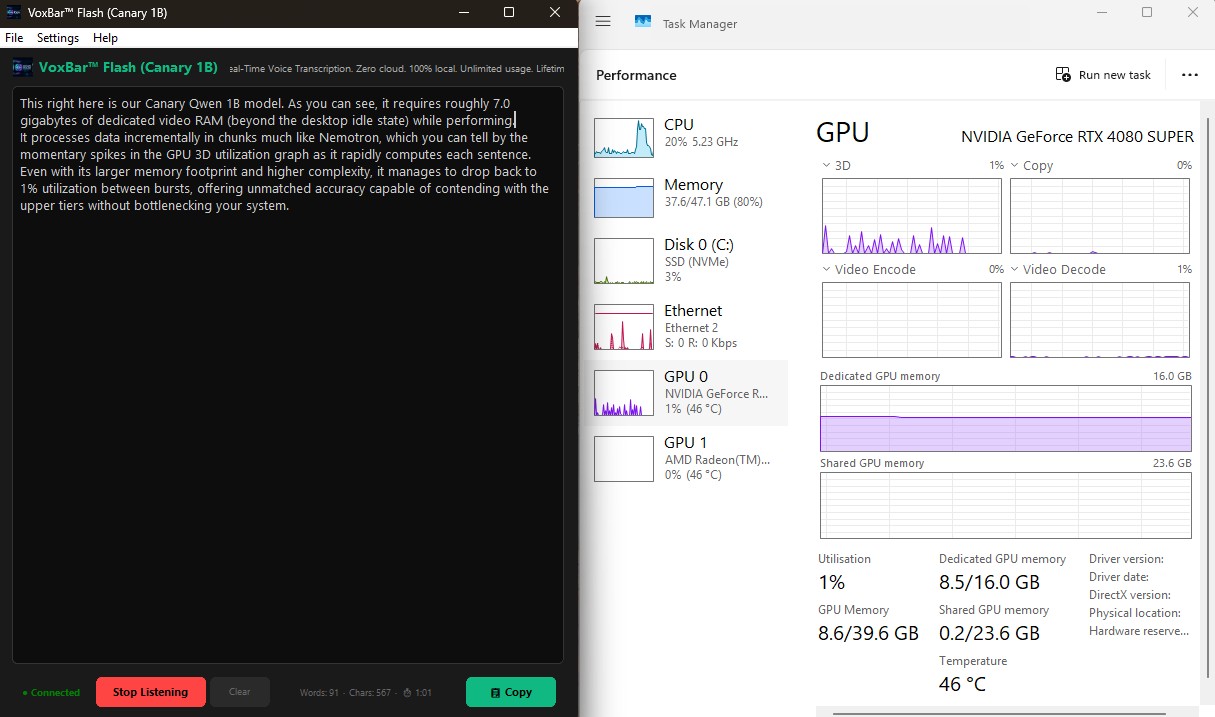
VoxBar Flash (Canary 1B)
This right here is our lightweight Canary Qwen 1B model variant for VoxBar Flash. As you can
see, it requires roughly 7GB of Dedicated VRAM
(beyond the
desktop idle state) while performing.
Just like its larger sibling, it processes data incrementally in chunks, producing
momentary spikes in GPU 3D utilization as it computes. Thanks to its smaller footprint, it
easily drops back down to 1% utilization between bursts, offering unmatched
accuracy with minimal strain on your system resources.
Multilingual Balanced Engine
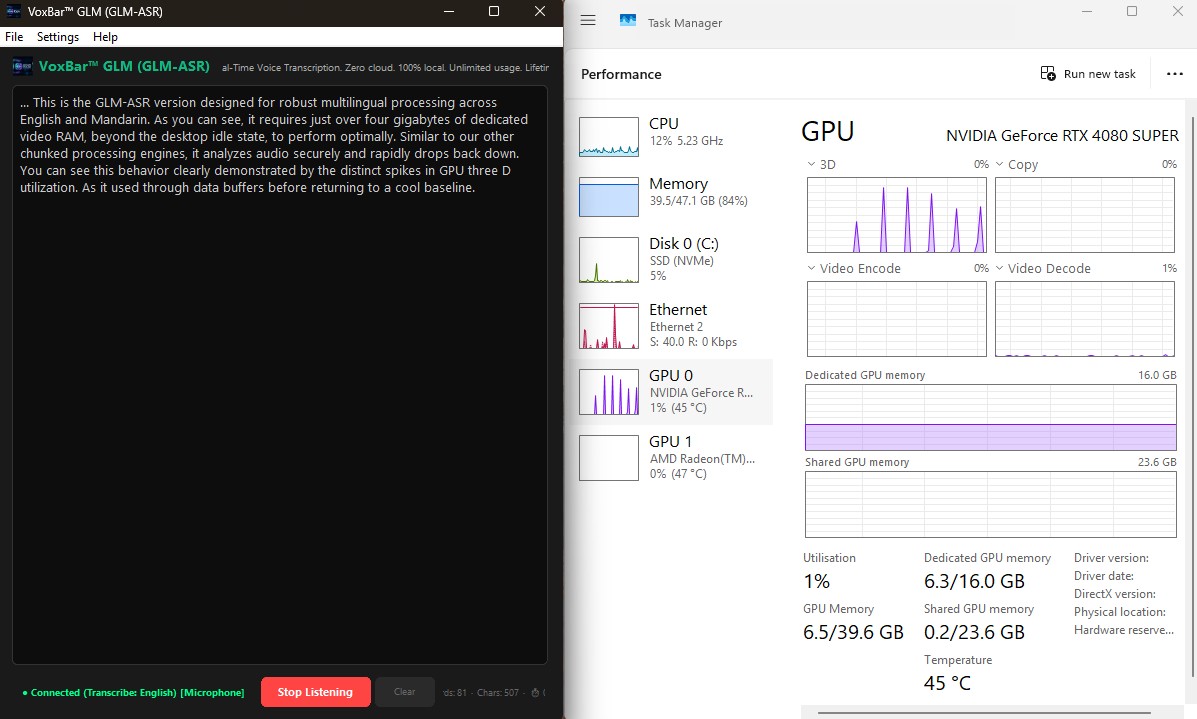
VoxBar GLM (GLM-ASR Nano 2512)
This is the GLM-ASR version, designed for robust multilingual processing across English and
Mandarin. As you can see, it requires just over 4GB of
Dedicated
VRAM (beyond the desktop idle state) to perform optimally.
Similar to our other chunked processing engines, it analyzes audio securely and
rapidly
drops back down. You can see this behavior clearly demonstrated by the distinct spikes in
GPU 3D
utilization as it chews through data buffers, before returning to a cool baseline.
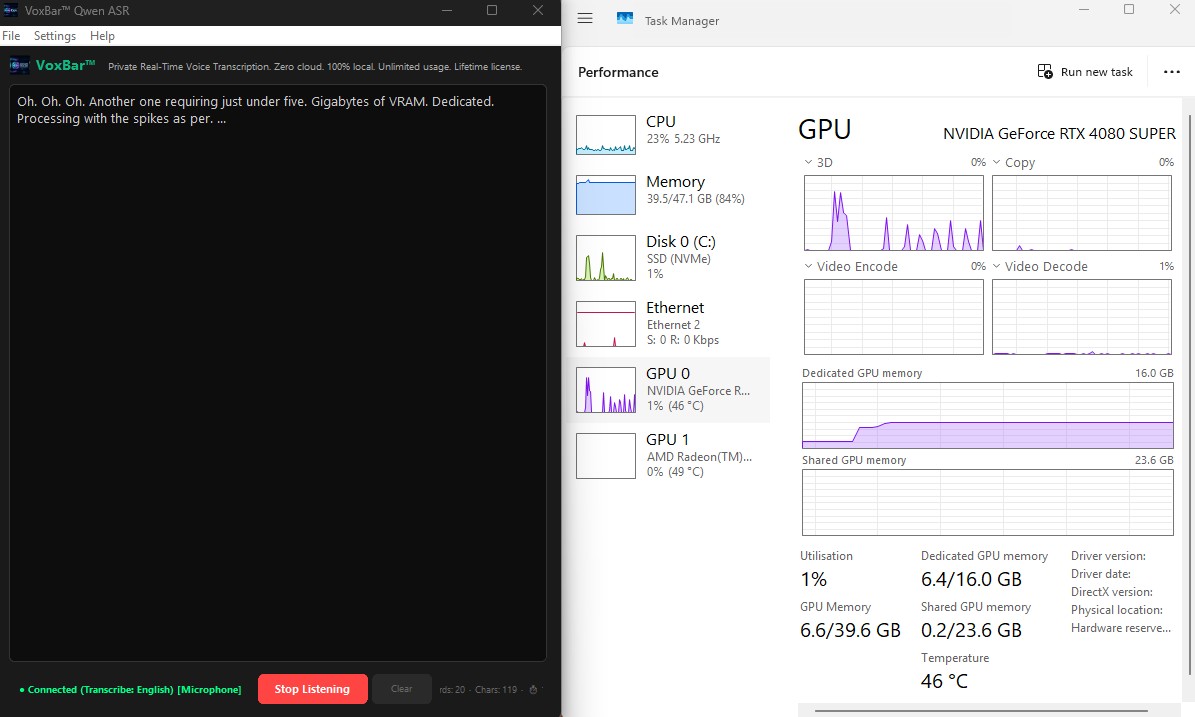
Advanced Generative Engine
VoxBar Qwen (Qwen3-ASR 1.7B)
This is the Qwen3-ASR engine running a highly optimized 1.7 billion parameter generative
model.
As you can see, it requires just under 4.5GB of Dedicated
VRAM
(beyond the desktop idle state) for operation.
Similar to our previous variants, it processes chunks of audio at once. The spikes
in
the GPU 3D utilization graph reflect this burst methodology, ensuring that the model rests
completely between computations, offering you a highly accurate transcription loop that
won't
lag your workflow.
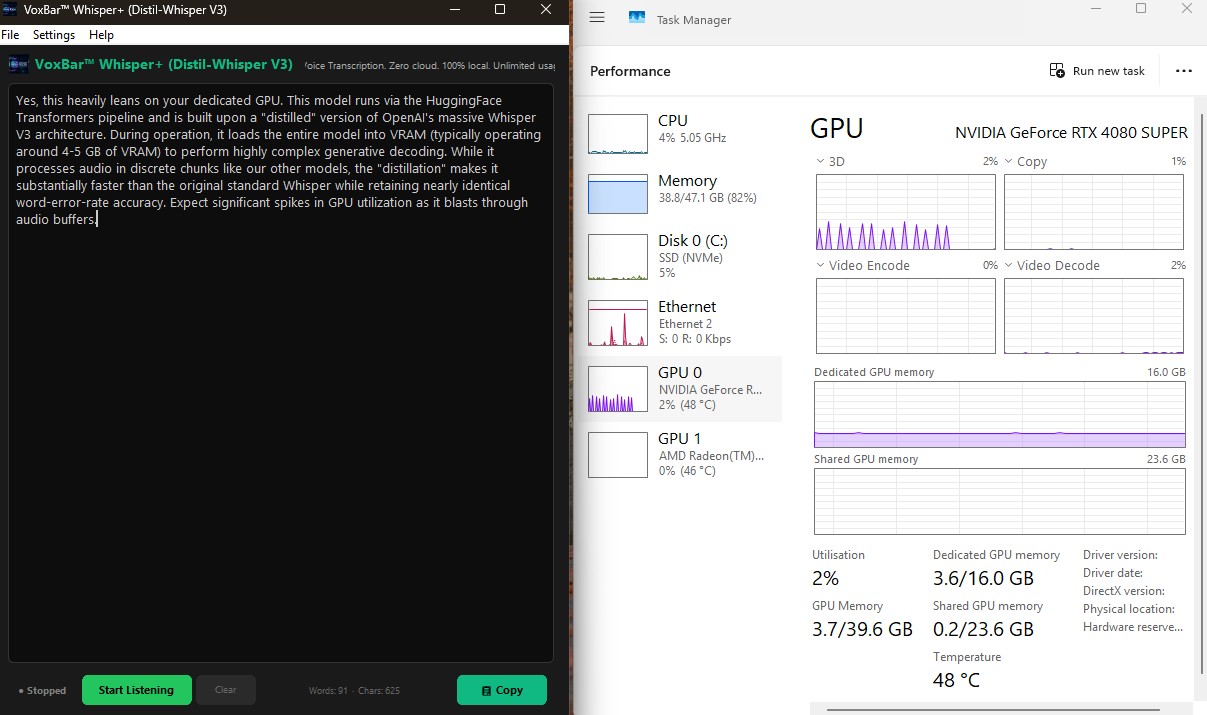
Hugging Face Transformers Engine
VoxBar Whisper+ (Distil-Whisper V3)
Yes, this heavily leans on your dedicated GPU. This model runs via the HuggingFace
Transformers
pipeline and is built upon a "distilled" version of OpenAI's massive Whisper V3
architecture.
During operation, it loads the entire model into VRAM (typically operating around
2GB of Dedicated
VRAM) to perform highly complex generative decoding.
While it processes audio in discrete chunks like our other models, the
"distillation"
makes it substantially faster than the original standard Whisper while retaining nearly
identical word-error-rate accuracy. Expect significant spikes in GPU utilization as it
blasts
through audio buffers.
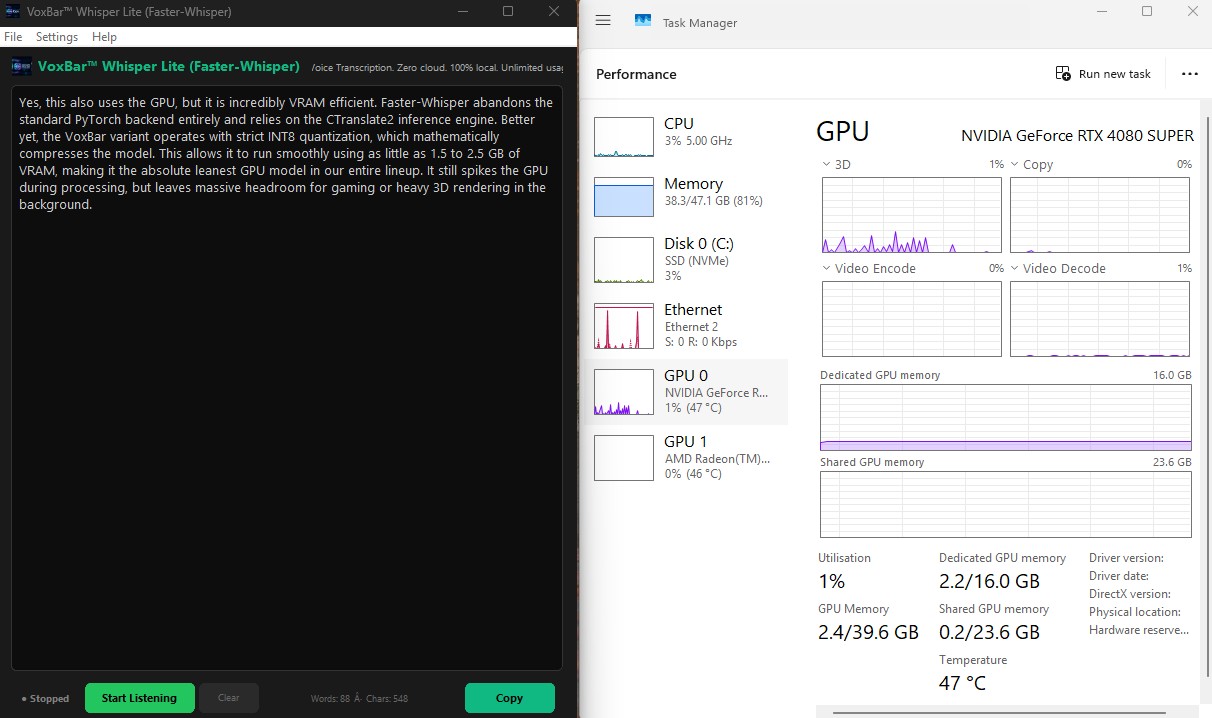
CTranslate2 Inference Engine
VoxBar Whisper Lite (Faster-Whisper)
Yes, this also uses the GPU, but it is incredibly VRAM efficient. Faster-Whisper abandons
the
standard PyTorch backend entirely and relies on the CTranslate2 inference engine.
Better yet, the VoxBar variant operates with strict INT8 quantization, which
mathematically compresses the model. This allows it to run smoothly using as little as
0.5GB of Dedicated VRAM, making it the absolute
leanest GPU model in our
entire
lineup. It still spikes the GPU during processing, but leaves massive headroom for gaming or
heavy 3D rendering in the background.